Hive - 数据存储格式详解3(SequenceFile格式)
三、SequenceFile 格式
1,基本介绍
(1)SequenceFile 是一种二进制文件,内部数据是 <Key,Value> 的形式,也属于行存储。
(2)SequenceFile 的特点是使用方便,MapReduce 原生支持这种数据格式,并且它还支持切分,也支持压缩。它可以支持 NONE、RECORD、BLOCK 级别的压缩。
- NONE 表示不压缩
- RECORD 表示行级别的压缩
- Block 表示块级别的压缩
提示:由于 Record 是针对每一条数据分别进行压缩,压缩率比较低,所以一般都会选择 Block 压缩。
2,不使用压缩
(1)首先我们执行如下命令在 Hive 中创建一个 SequenceFile 存储格式的表。注意:在这需要使用 stored as 指定 sequencefile 存储格式,不指定的话默认是 textfile。
1 2 3 4 5 6 7 8 9 10 | create external table stu_seqfile_none_compress( id int, name string, city string)row format delimitedfields terminated by ','lines terminated by '\n'stored as sequencefilelocation '/stu_seqfile_none_compress'; |
(2)创建后执行如下命令确认一下这个表,如果 INPUTFORMAT 使用的是 SequenceFileInputFormat,说明这个表中需要存储 SequenceFile 格式的数据。
1 | show create table stu_seqfile_none_compress; |

(3)然后从普通表中查询数据导入到这个 SequenceFile 存储格式的表中。
- 在这里我们设置 mapreduce.job.reduces=1,表示将结果数据写入到一个数据文件中,这也便于后面验证这个数据文件是否支持 Split。
普通表 stu_textfile 中的数据来源可以参考我前面写的文章:Hive - 数据存储格式详解 2(TextFile 格式)
1 2 | set mapreduce.job.reduces=1;insert into stu_seqfile_none_compress select id,name,city from stu_textfile group by id,name,city; |
(4)查看结果数据可以发现,其体积与原始的 TextFile 文件相当,也要 2G 左右。

(5)接下来写一个 sql 查询表中的数据,验证是否支持切分:
1 | select id,count(*) from stu_seqfile_none_compress group by id; |
- 可以看到产生了 11 个 map 任务,说明 SequenceFile 格式的文件支持切分。

(6)如果读取 SequenceFile 格式的文件中的数据是什么样子的,可以参考我之前写的文章:
(7)最后,这个表中的数据验证完毕之后,建议删除一下数据,释放 HDFS 空间。
1 | hdfs dfs -rm -r -skipTrash /stu_seqfile_none_compress |
3,使用 Defalte 压缩格式(Block 级别)
(1)接下来我们构建一个新的压缩数据表。
提示:这个压缩数据表的建表语句和不使用压缩数据表建表语句没有区别,唯一的区别就是在向表中添加数据的时候指定数据压缩格式。
1 2 3 4 5 6 7 8 9 10 | create external table stu_seqfile_deflate_compress( id int, name string, city string)row format delimitedfields terminated by ','lines terminated by '\n'stored as sequencefilelocation '/stu_seqfile_deflate_compress'; |
(2)Hive 中默认是没有开启压缩的,我们执行如下命令开启 Hive 输出数据压缩功能,并且指定使用 deflate 压缩,Block 级别。
1 2 3 4 | set hive.exec.compress.output=true;set mapreduce.output.fileoutputformat.compress=true;set mapreduce.output.fileoutputformat.compress.codec=org.apache.hadoop.io.compress.DeflateCodec;set io.seqfile.compression.type=BLOCK; |
- 如果后期不确定使用的是哪种压缩格式,可以通过这条命令查看:
1 | set mapreduce.output.fileoutputformat.compress.codec; |
(3)接下来通过 insert into select 从普通表中查询数据,插入到压缩表中。
- 在这里我们设置 mapreduce.job.reduces=1,表示将结果数据写入到一个数据文件中,这也便于后面验证这个数据文件是否支持 Split。
注意:为了能够控制任务最终产生的数据文件个数,在这里通过 mapreduce.job.reduces 来控制,并且 SQL 语句中需要有可以产生 shuffle 的操作,如果是普通的 select 语句,最终是不会产生 Reduce 任务的,那么 mapreduce.job.reduces 这个参数就无法生效了。
1 2 | set mapreduce.job.reduces=1;insert into stu_seqfile_deflate_compress select id,name,city from stu_textfile group by id,name,city; |
- 可以看到最终产生的数据文件大小为 354M:

(4)接下来写一个 sql 查询压缩表中的数据,确认一下是否验证是否支持切分:
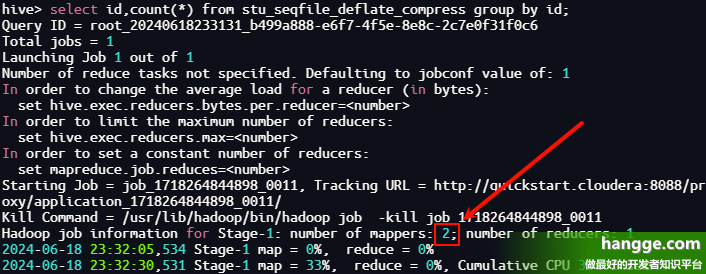
1 | select id,count(*) from stu_seqfile_deflate_compress group by id; |
- 在这里看到产生了 2 个 map 任务,说明 SequenceFile 格式带压缩的文件也支持切分。
(5)最后,这个压缩表中的数据查看后最好删除一下,这样可以释放 HDFS 存储空间。
1 | hdfs dfs -rm -r -skipTrash /stu_seqfile_deflate_compress |
附:为什么 SequenceFile 格式带压缩的文件也支持切分?
(1)通过上面的测试我们可以发现 SequenceFile 格式带压缩的文件也支持切分。这是因为 SequenceFile 这个文件自身是支持切分的,我们现在的压缩是针对文件内部的数据进行压缩,并不会改变 SequenceFile 的特性。这一点和 TextFile 就不一样了。
- 所以说在 SequenceFile 中使用压缩的时候就不需要考虑压缩格式自身是否支持切分的特性了,主要考虑的是压缩格式的压缩比、以及压缩解压速度这些指标。
(2)我们可以通过下面图进行理解:
- 上面表示是 SequenceFile 中的数据,每一个 Record 代表里面的一条数据。
- 当没有压缩的时候,Record 内部存储的是 Record 的长度、key 的长度、key 和 value。
- 当使用 Record 级别压缩的时候,Record 内部存储的是 Record 的长度、key 的长度、key 和压缩之后的 Value。

- 当使用 Block 级别压缩的时候,SequenceFile 中的数据是以 Block 为单位存储的,每个 Block 中存储多个 Record,并且对 Block 内部的多个 Record 统一压缩存储。
- 所以这里的压缩是针对 SequenceFile 内部数据的压缩,并没有改变 SequenceFile 自身的特性,所以他依然是可以支持切分的。

